Bayesian Statistics
Update our belief based on the data
Posted on September 2023
The ability to estimate parameters based on data in maximum likelihood estimation is powerful. However, there is some caveat if we only rely on data. Take a process of a fair coin toss for example, there are two spaces, either the coin lands in head or tail. We do 10 tosses of coin, then the result shows that 7 out of 10 tosses result in head while only 3 result in tail. Then we model this using Bernoulli distribution and estimate its parameter using maximum likelihood estimation. We find that there is a 0.7 probability that a coin toss will land on heads.
Well this is clearly a false model, far from the truth. We know that a fair coin has about 50-50 in either landing on head or tail. But the data that we observed differ from this belief. If we do 10 tosses again then we might have 4 heads and 6 tails which result in a different model from previously.
Turns out to make an inference, we also need prior belief or model. This is the beginning of Bayesian statistics.
Bayes Theorem
Bayes theorem says that the probability of an event $A$ given $B$ is proportional to the probability of an event $B$ given $A$ times the probability of $A$, mathematically
\[p(A \mid B) \propto p(B \mid A) \times p(A)\]Now if we apply this theorem to the process and data relationship we get: the probability of a parameter from model given the data (what we are trying to do earlier) is proportional to the probability of the data given the parameter times the probability of the parameter, mathematically
\[p(\theta{} \mid Y) \propto p(Y \mid \theta{}) \times p(\theta)\]The probability of the data given the parameter is identical to the likelihood function of the parameter and we have
\[p(\theta{} \mid Y) \propto L(\theta{} \mid Y) \times p(\theta)\]Usually, the product of likelihood function and prior distribution does not result in a nice function to be solved analytically. So in practice, simulation is used to create new data from posterior distribution. Then we can calculate the confidence interval for the parameter.
Example of Bayesian Analysis in Python using pymc
Below is an example of Bayesian analysis using pymc3. Pymc3 is a probabilistic programming language (PPL) that expands computer capabilities to do bayesian analysis. I only learned about PPL at the time of this writing. Maybe I will write about this next time.
import pandas as pd
import arviz as az
import pymc as pm
Process: 10 tosses of coin, 7 heads and 3 tails. Head:1, tail:0
tosses = [1, 0, 1, 1, 0, 1, 0, 1, 1, 1]
df = pd.DataFrame(tosses, columns=["Outcomes"])
df.value_counts()
Outcomes
1 7
0 3
dtype: int64
prior_prob=df.value_counts()[1]/len(tosses)
basic_model = pm.Model()
with basic_model:
# Parameter for prior, the sigma is 0.05 because we are so sure that a coin toss have a probability 0.05 to land on head
p = pm.Normal('p', mu=0.5, sigma=0.05)
# Likelihood
posterior_prob = pm.Bernoulli("Posterior", p=p, observed=tosses)
with basic_model:
# draw 500 posterior samples
trace = pm.sample(500, return_inferencedata=True)
Below is the distribution of the parameter p (or the probability in this case because the use of Bernoulli distribution)
with basic_model:
az.plot_trace(trace);
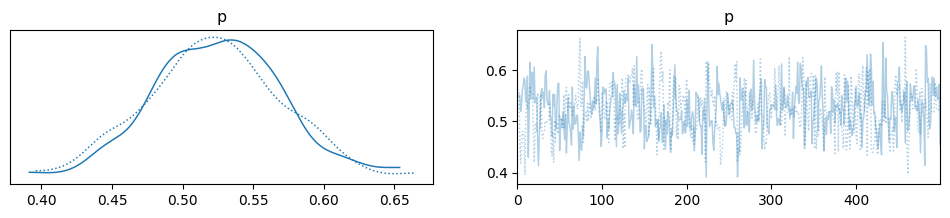
Below is the descriptive statistics of the parameter
with basic_model:
display(az.summary(trace, round_to=2))
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| p | 0.52 | 0.05 | 0.44 | 0.6 | 0.0 | 0.0 | 447.8 | 779.37 | 1.0 |
with basic_model:
az.plot_posterior(trace);
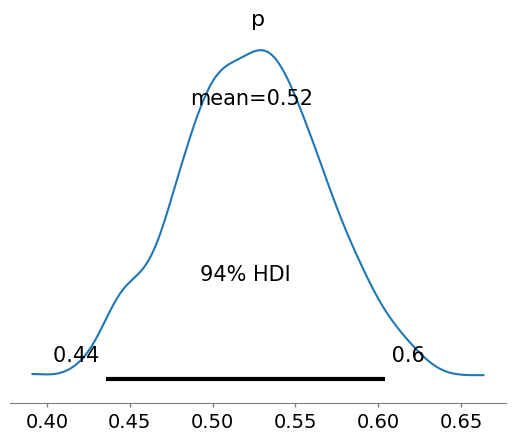
As we can see we have updated our initial belief about the data to be closer to the data.